Calculation blocks: Part 1
Why we use calculation blocks
To obtain the worked example file to accompany this chapter buy the financial modelling handbook.
We are going to build a model together based on a solar acquisition case study. One of our first jobs will be to model electricity generation revenue.
If you've ever seen a model before, you'll be familiar with something that looks like this:
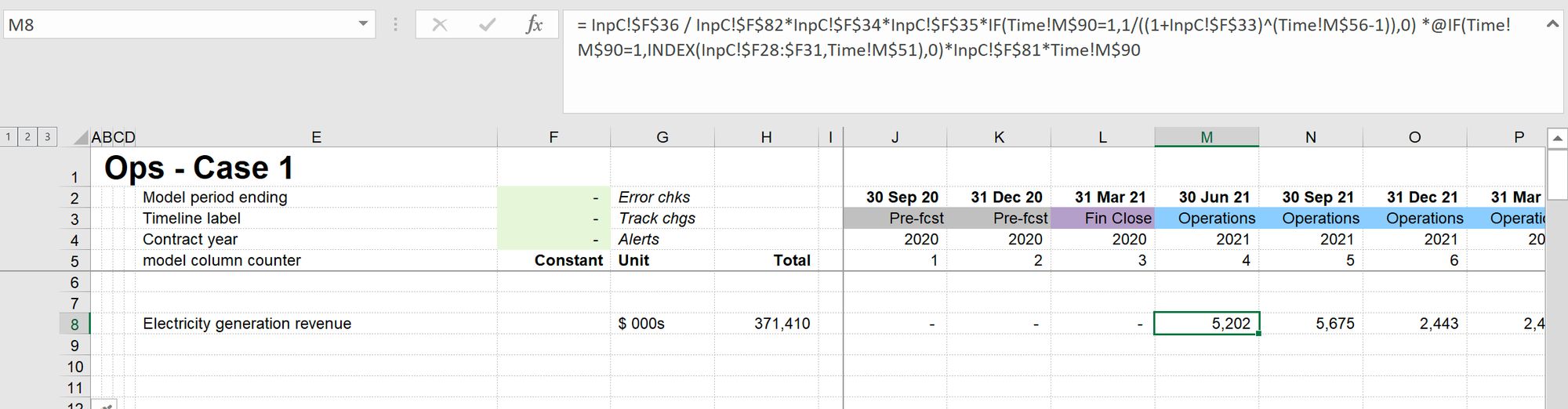
The modeller here has calculated revenue in a single line. They have used lots of off sheet references. Most likely, this is what you've seen in most models you've looked at in the past.
Here’s the formula in full:
What's good about this?
It's compact. We have only taken up one row in the model.
What's not good about this?
It's horrible to read and make sense of. To understand the formula, we have to hunt around the model to find each component.
Without going to the input sheet and looking, I have no way of knowing that the first item that the formula is referencing (InpC!$F$36) is the power tariff. I have to go to the input sheet, find that item, see what it is, see what the value is, then come back to where I started. And I have to repeat the process for each item within the formula.
Our conscious brains can hold between 4 and 7 chunks of information at a time. Given how long some formulas are, it won't be long before we run out of mental storage space.
If I chart revenue, I get a profile like this:
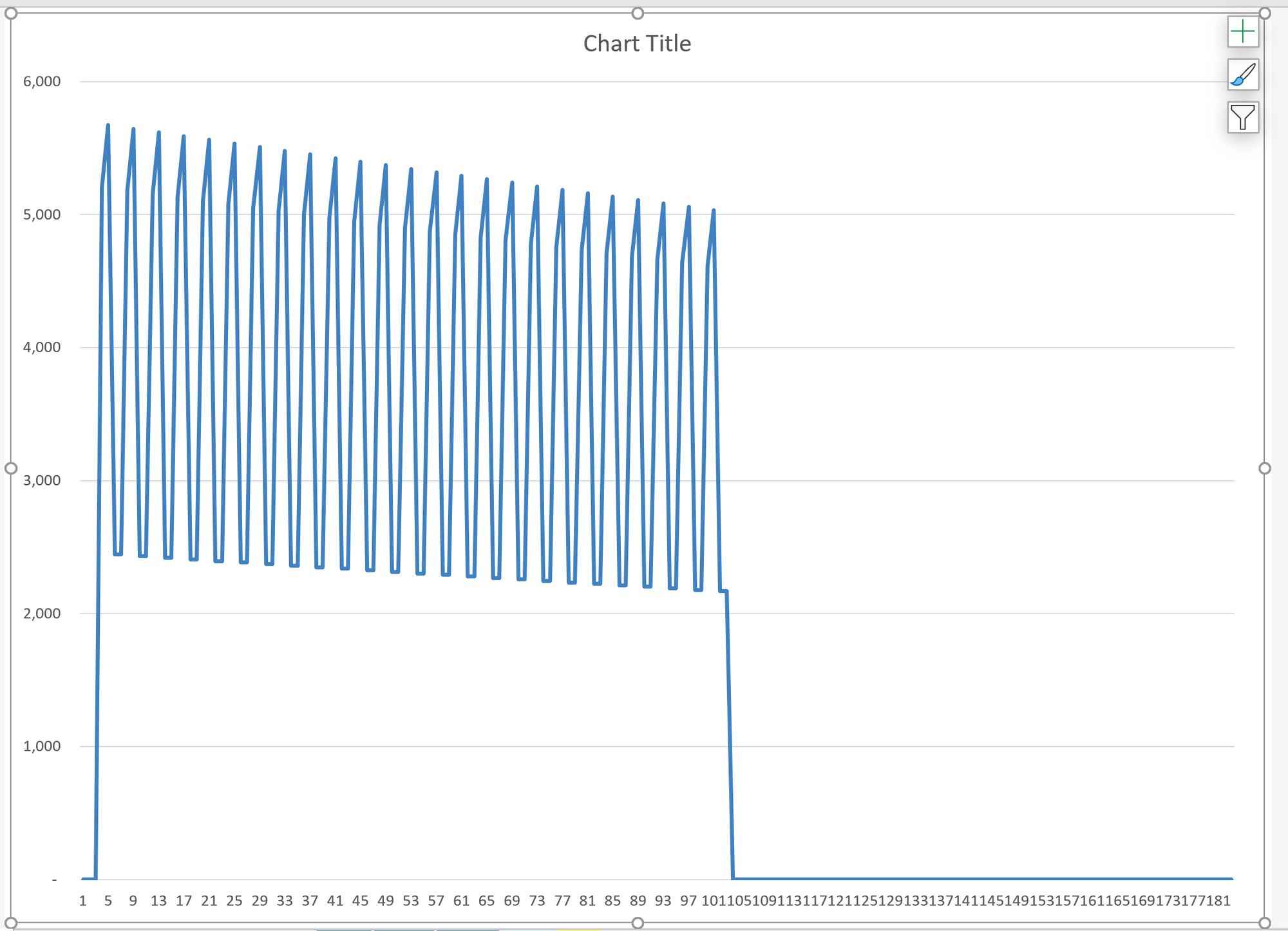
What is causing the spikes? What is causing the downward slope? Looking at just this formula, I have no way of knowing which of the ingredients are causing these effects.
So apart from the fact that it only takes up one row, there is very little to recommend this approach to writing formulas in models.
Here is the same calculation, laid out in blocks.
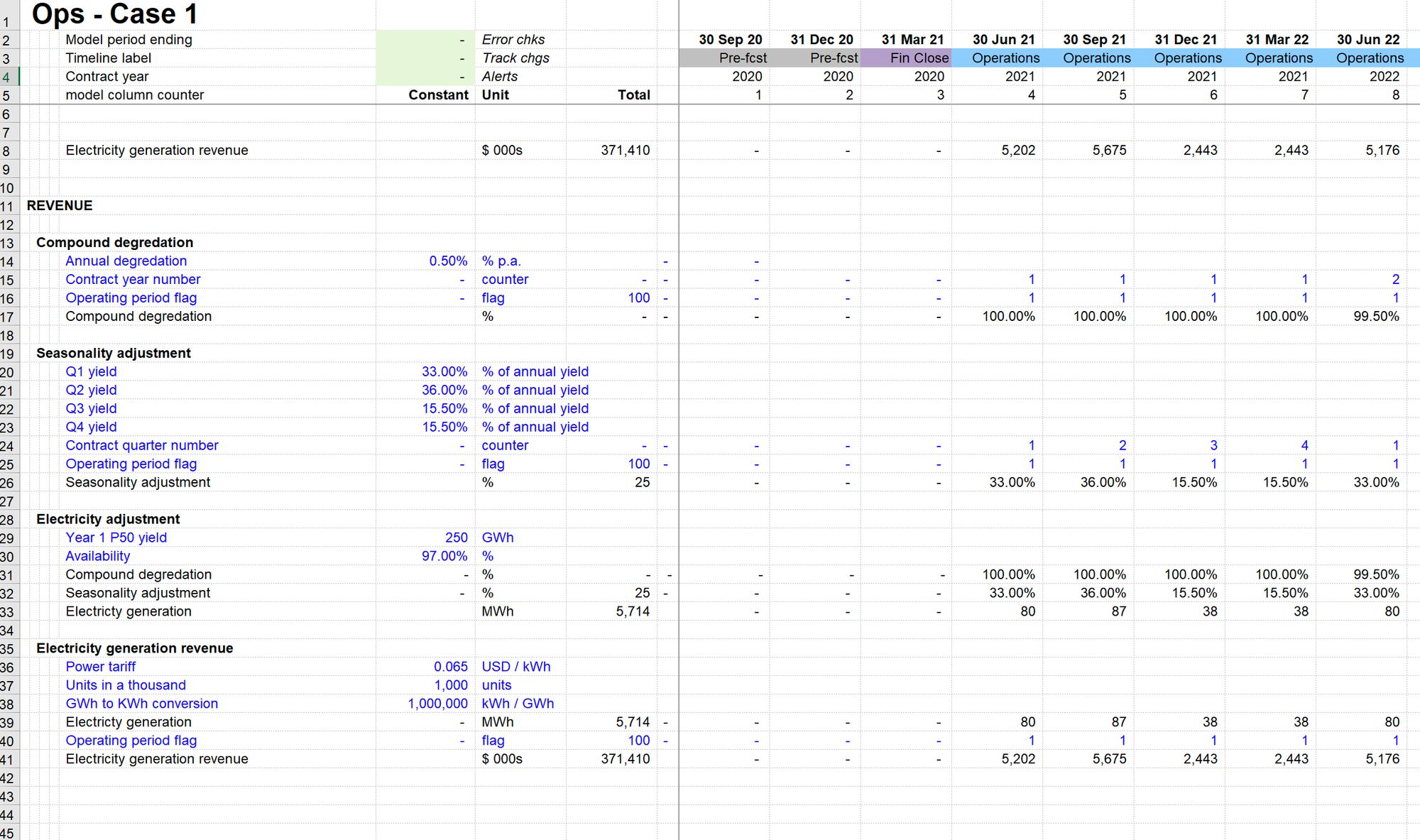
You can see that the formula in row 41 gives the same answer as the calculation in row 8. You can therefore see that this is the same calculation. It's just the layout that's different.
The difference is that when we lay the calculation out in blocks, we can see all the precedents.
At this point, you may be thinking, "Holy crap, Kenny, you've just taken 30 rows to do a calculation that you could do in one." And that is the "downside" of this approach - it uses rows. But rows are free. There isn't a row shortage. And the advantages outweigh any downside of overly abundant row usage.
So what's good about this approach?
Readability:
- The formula is much, much shorter. The reader requires much less work to figure out what the formula is doing.
- All of the ingredients driving electricity generation are right next to the calculation. With their labels. And their values. I have to read them. No paging around the model. No trying to hold lots of facts in my head simultaneously.
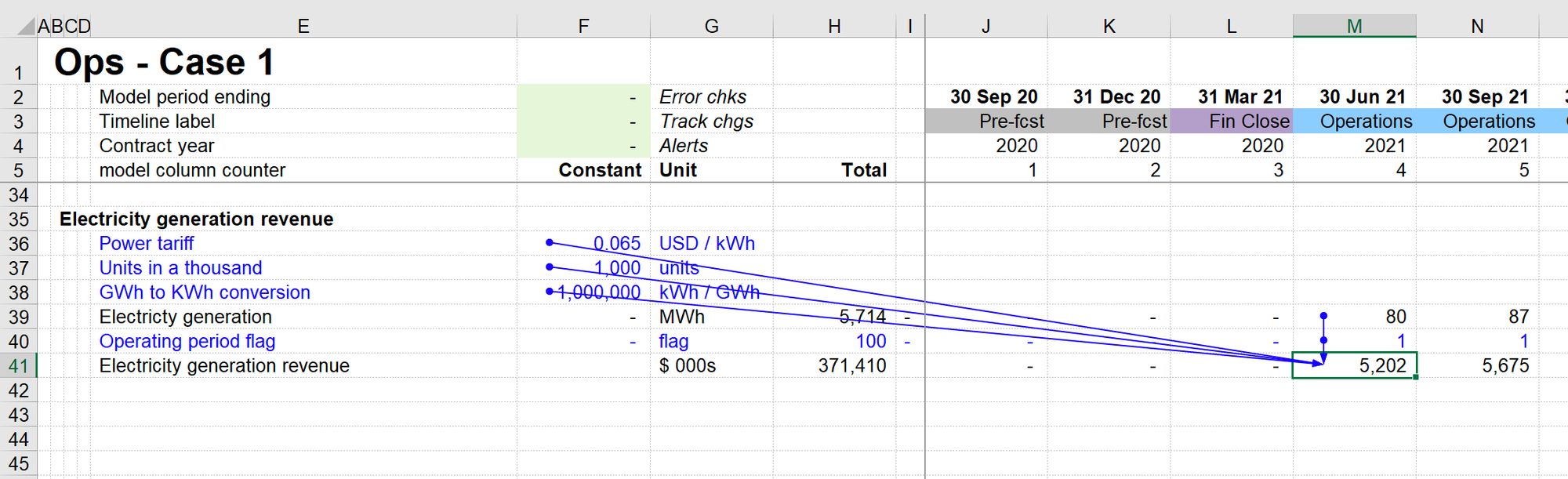
One of the ways I've made the formula simpler is by breaking it up into several smaller, easier to understand steps.
For example, I have broken out the calculation of electricity generation into a separate block with its own ingredients. The result of this calculation block is feeding into my revenue block. I can review a simple formula while having immediate visibility over the components.
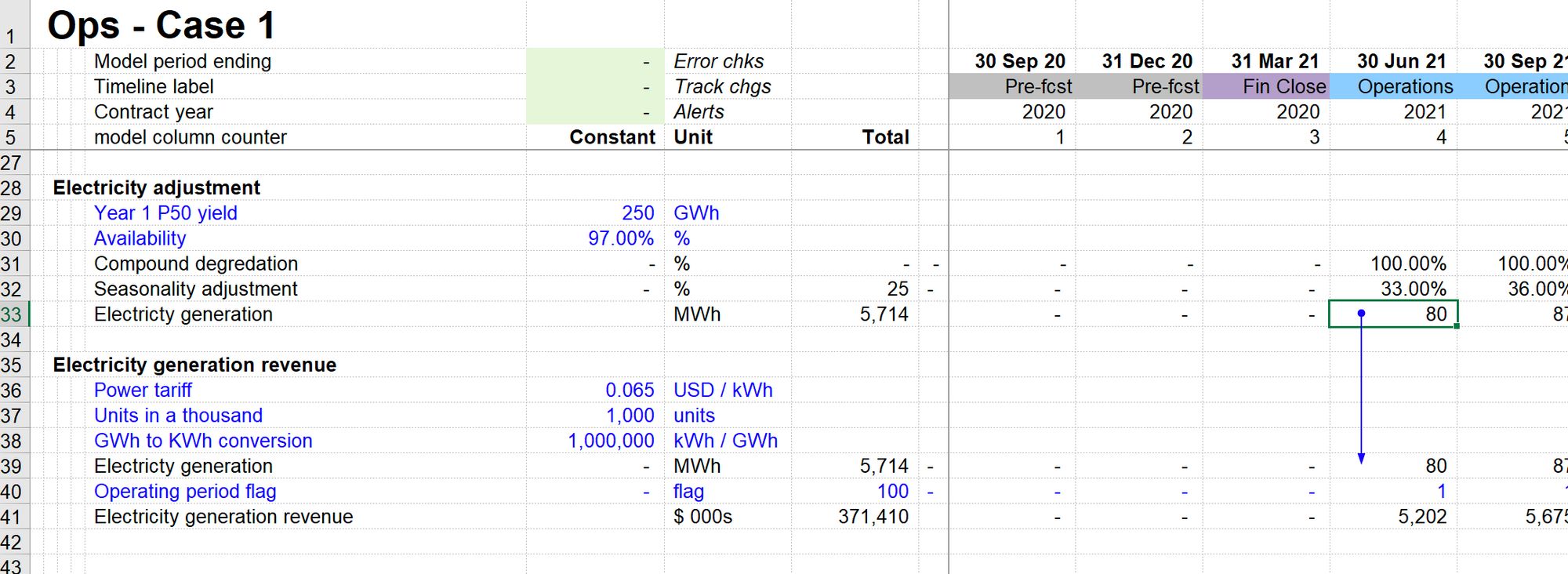
Since all the ingredients are now visible, I can see the line items causing revenue to have the profile I saw in the chart. I can see this without hunting around the model and spending time trying to figure it out. It's all right in front of me.
I can see that the Seasonality adjustment is responsible for the spikes in revenue. I can see that degradation is responsible for the downward slop in revenue.
Next up, we'll look at what goes into building a calculation block.

Comments
Sign in or become a Financial Modelling Handbook member to join the conversation.
Just enter your email below to get a log in link.